
반응형
 [Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
[Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
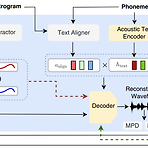
StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language ModelsHuman-level text-to-speech를 위해 large speech language model (SLM)을 활용할 수 있음StyleTTS2Diffusion model을 통해 style을 latent random variable로 모델링하여 reference speech 없이 text에 적합한 style을 생성End-to-End training을 위해 differentiable duration modeling이 가능한 discriminator를 도입하고 large pre..
Paper/TTS
2024. 3. 17. 13:45
반응형