

반응형
 [Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
[Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
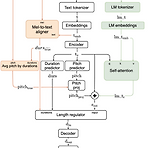
Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model EmbeddingsMel-spectrogram generation에서는 non-autoregressive 모델이 유용함Mixer-TTSMLP-Mixer architecture를 기반으로 pitch/duration predictor를 활용Pre-trained language model의 token embedding을 추가적으로 도입하여 Mixer-TTS를 extend논문 (ICASSP 2022) : Paper Link1. IntroductionText-to-Speech (TTS)에서는 속도 향상을 위해서는 non-autoregres..
Paper/TTS
2024. 2. 26. 10:08
반응형