

반응형
 [Paper 리뷰] GenerSpeech: Toward Style Transfer for Generalizable Out-of-Domain Text-to-Speech
[Paper 리뷰] GenerSpeech: Toward Style Transfer for Generalizable Out-of-Domain Text-to-Speech
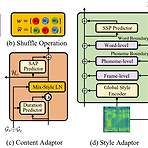
GenerSpeech: Towards Style Transfer for Generalizble Out-of-Domain Text-to-SpeechOut-of-Domain 음성 합성을 위해 style transfer를 활용할 수 있지만 몇 가지 한계가 존재함- Expressive voice의 dynamic style feature는 모델링과 transfer가 어려움- Text-to-Speech 모델은 source data와 다른 Out-of-Domain condition을 handle 할 수 있을 만큼 robust 해야 함GenerSpeechOut-of-Domain custom voice에 대해 high-fidelity zero-shot style transfer를 가능하게 하는 text-to-speech..
Paper/TTS
2024. 1. 30. 15:07
반응형