
반응형
 [Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
[Paper 리뷰] FedSpeech: Federated Text-to-Speech with Continual Learning
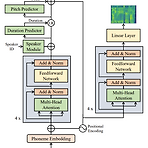
FedSpeech: Federated Text-to-Speech with Continual Learning Federated text-to-speech는 여러 사용자의 음성을 device에 locally store 된 few audio sample과 합성하는 것을 목표로 함 Federated text-to-speech는 각 speaker에 대한 training sample이 거의 없고, sample이 각 local device에만 store 되어 있고, global model이 다양한 공격에 취약하다는 어려움이 있음 FedSpeech Gradual pruning mask를 사용하여 speaker tone을 preserving 하기 위해 parameter를 isolate 함 Task에서 얻은 knowled..
Paper/TTS
2024. 2. 22. 11:21
반응형