

반응형
 [Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
[Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
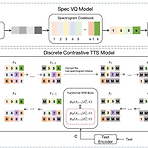
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation Text-to-Speech에서 latent diffusion model을 우수한 성능을 보이고 있지만, resource consumption이 크고 추론 속도가 느림 DCTTS Discrete diffusion model과 contrastive learning을 결합한 text-to-speech 모델 간단한 text encoder와 VQ model을 사용하여 raw data를 discrete space로 compress 한 다음, discrete space에서 diffusion model을 training 함 이때 diffusion step 수를 줄..
Paper/TTS
2024. 4. 19. 09:29
반응형