
반응형
 [Paper 리뷰] XTTS: A Massively Multilingual Zero-Shot Text-to-Speech Model
[Paper 리뷰] XTTS: A Massively Multilingual Zero-Shot Text-to-Speech Model
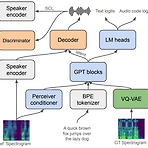
XTTS: A Massively Multilingual Zero-Shot Text-to-Speech Model대부분의 zero-shot multi-speaker text-to-speech 모델은 single language만 지원함XTTS16개의 다양한 low/medium resource language로 task를 확장Multilingual training을 지원하고 voice cloning을 개선하여 빠른 training/추론 속도를 달성논문 (INTERSPEECH 2024) : Paper Link1. IntroductionZero-shot multi-speaker Text-to-Speech (ZS-TTS)는 few-second speech를 기반으로 unseen speaker에 대한 음성 합성을 목..
Paper/TTS
2024. 6. 30. 09:56
반응형