

반응형
 [Paper 리뷰] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
[Paper 리뷰] VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
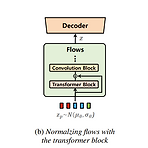
VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture DesignSingle-stage text-to-speech model은 기존의 two-stage 방식보다 더 우수한 합성 품질을 보이고 있지만, phoneme conversion에 대한 dependency와 computational efficiency 측면에서 개선이 필요함VITS2기존의 VITS structure를 개선하여 보다 natural 한 음성 합성과 multi-speaker에서 더 나은 speaker similarity를 지원Fully end-to-end single-stage approac..
Paper/TTS
2024. 6. 5. 10:45
반응형