

반응형
 [Paper 리뷰] VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
[Paper 리뷰] VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
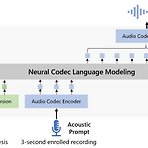
VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech SynthesizersText-to-Speech를 위해 language modeling을 활용할 수 있음VALL-ENeural audio codec에서 파생된 discrete code를 사용하여 training 된 language model기존의 continuous signal regression이 아닌 conditional language modeling으로 text-to-speech를 접근특히 in-context learning capability를 제공하여 unseen speaker를 3초 이내의 acoustic prompt를 통해 personalized speech를 합성 가능논문..
Paper/Language Model
2024. 6. 15. 11:55
반응형