

반응형
 [Paper 리뷰] DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning
[Paper 리뷰] DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning
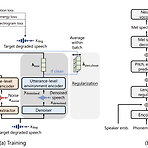
DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning대부분의 text-to-speech system은 well-designed 환경에서 수집된 고품질 corpus를 활용하므로 데이터 수집 비용이 높음DRSpeechNoisy speech corpora를 training data로 활용할 수 있는 noise-robust text-to-speech 모델Frame-level encoder를 통해 time-variant additive noise를 represent 하고 utterance-level encoder를 사용하여 time-invarian..
Paper/TTS
2024. 7. 4. 09:09
반응형