

반응형
 [Paper 리뷰] Grad-StyleSpeech: Any-Speaker Adaptive Text-to-Speech Synthesis with Diffusion Models
[Paper 리뷰] Grad-StyleSpeech: Any-Speaker Adaptive Text-to-Speech Synthesis with Diffusion Models
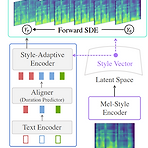
Grad-StyleSpeech: Any-Speaker Adaptive Text-to-Speech Synthesis with Diffusion Models Any-speaker adaptive Text-to-Speech 작업은 여전히 target speaker의 style을 모방하기에 만족스럽지 못함 Grad-StyleSpeech Diffusion model을 기반으로 하는 any-speaker adaptive Text-to-Speech model Few-second reference speech가 주어지면 target speaker와 유사한 음성을 생성하는 것을 목표로 함 논문 (ICASSP 2023) : Paper Link 1. Introduction Text-to-Speech (TTS)는 single..
Paper/TTS
2024. 2. 9. 12:43
반응형